
AI Hallucinations in Practice
New research from OpenAI on hallucinations confirms what we’ve thought for a long time—GenAI training methods reward confident guesses over uncertainty.
The result? ChatGPT and other foundation models are often confidently wrong.
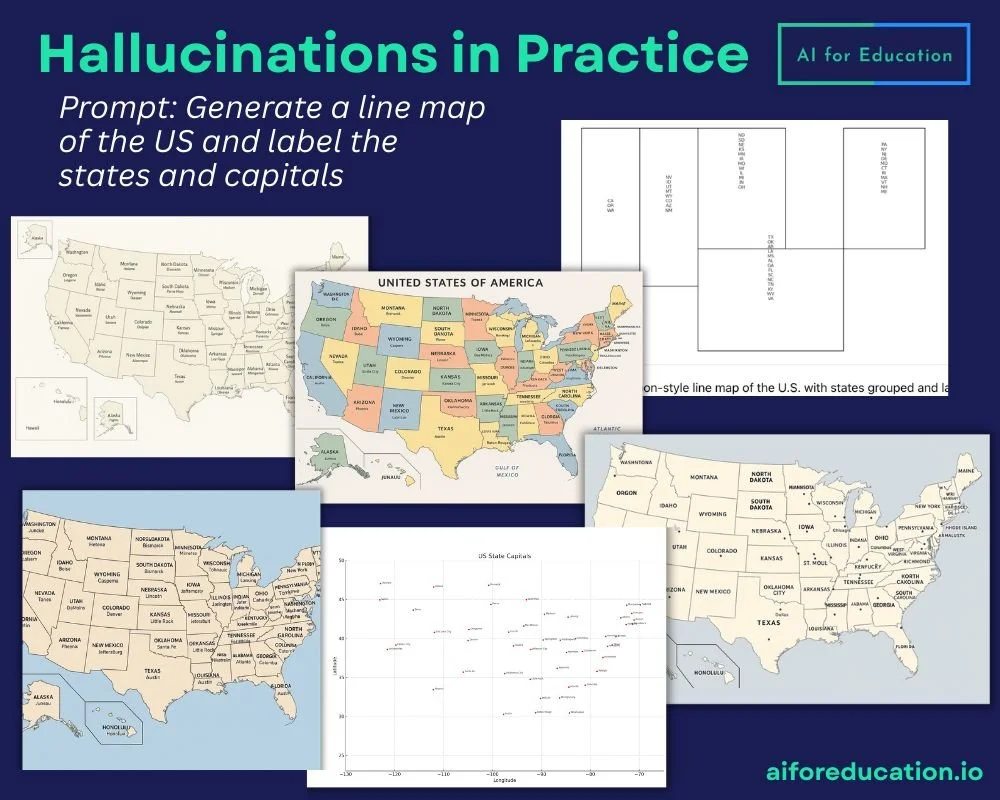
Which is why we spend time in every training to show GenAI's tendency to hallucinate (provide inaccurate information). As GenAI has improved, we've had to change our demo. We've gone from acrostic poems to counting the r's in "strawberry" to now asking ChatGPT to create a map of U.S. states and capitals.
What happens during the map exercise is that ChatGPT fails in funny and unexpected ways. It usually does a good job on the state boundaries, but it all goes awry when it comes to the labels. Mississippi becomes “Maisisipor”, or Austin is now the entire Southwest.
When we ask the bot to analyze and rate its output, it confidently does so and offers to create a new, corrected map. Which it absolutely cannot, highlighting not only hallucinations, but also its tendency towards sycophancy.
What’s unexpected is that since ChatGPT-5’s release, the map outputs have gotten even worse and sometimes not even maps.
This exercise is a great way to build AI literacy as it demonstrates how even the most advanced AI systems can struggle with tasks that seem straightforward and basic. It's a perfect teachable moment that reinforces the need for critical evaluation of all GenAI outputs.
Hopefully, OpenAI’s new research puts a path forward towards figuring out how tech companies can lower hallucinations moving forward, but until then we will continue having a bit of fun at ChatGPT’s expense.
You can read OpenAI's new research here.